[정리] 모두를 위한 딥러닝 07 - 실전 연습 및 팁 by 김성훈
강의 웹사이트 : http://hunkim.github.io/ml/
Lec = 강의 / Lab = 실습
러닝 레이트 learning rate 가 너무 크면 아래 그림과 같이 예측값이 아래로 수렴하는게 아니고,
밖으로 나가버리는 경우가 생깁니다.

반대로 러닝 레이트 learning rate 가 너무 작으면 좋은 예측을 못하거나 시간이 너무 오래 걸립니다.

그리고, 2차 함수를 3차원처럼 등고선으로 나타낼 수도 있습니다.
만약 x1, x2 두 값이 입력값인데, 차이가 너무 크다면 납작한 원이 될 수 있습니다.

이렇게 되면 데이터를 함수에 넣기 전에 먼저 적절한 처리를 해야 합니다.

이렇게 넓은 범위를 포함하고 있는 입력값이 있다면 이를 적절한 범위로 만드는 선 작업이 필요합니다.
그걸 프리 프로세싱. 노말라이제이션. 정규화 라고 부릅니다.
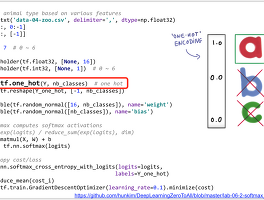
정규화를 위한 많은 알고리즘이 있지만 유명한 스탠다디제이션은 아래와 같습니다.

코드를 보니 파이썬으로 구현할때에는 좀 쉬워 보입니다.
다음에는 오버피팅이라는걸 살펴보겠습니다.

빨간 네모가 예측해야 하는 값이라면 이게 - 마이너스일까 + 플러스일까 쉽지 않습니다.
왼쪽 그래프로 본다면 - 마이너스가 되지만 (적절한 학습), 오른쪽 그래프로 보면 + 플러스가 됩니다.
- 마이너스가 맞는 값인데, 너무 정확하게 학습하면 + 플러스로 잘못 예측하게 됩니다.
이걸 오버피팅이라고 합니다.
경계선을 그을때 너무 구부리지 말아야 합니다.
어떻게 이렇게 할 수 있을까요?

많은 트레이닝 셋이 필요합니다. 데이터가 많아야 합니다.
너무 큰 값, 동떨어진 값, 특정값은 줄여야 합니다.
일반화를 시켜야 합니다.
이를 파이썬으로 구현하면 아주 쉽습니다.
square 함수를 사용하면 됩니다.

그래서 트레이닝 세트가 (기반 데이터가) 많으면 일부를 따로 뺍니다.
따로 남겨둔 데이터는 트레이닝을 하지 않고 모의 테스트를 진행합니다.

'Tech > 머신러닝' 카테고리의 다른 글
| 이미지 인식 인공지능을 방해하는 특정 이미지 - 지금은 효과가 없음. (0) | 2018.09.06 |
|---|---|
| 인공지능 - 이미지에서 텍스트 추출 OCR (0) | 2018.07.12 |
| [정리] 모두를 위한 딥러닝 08 - 딥러닝 개념 by 김성훈 (0) | 2018.06.15 |
| [정리] 모두를 위한 딥러닝 06 - Softmax Regression (0) | 2018.06.15 |
| 케라스 Keras 모델 저장, 재사용 (0) | 2018.06.12 |