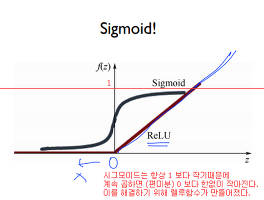
2018/06/12 (2) 썸네일형 리스트형 케라스 Keras 모델 저장, 재사용 케라스 Keras 모델 저장, 재사용 원본 : https://tykimos.github.io/2017/06/10/Model_Save_Load/ 에 있는 강좌를 정리했습니다. 위 링크는 김태영님의 케라스 강의 사이트입니다. 딥러닝 Deep Learning 케라스 Keras 에서 아래와 같은 방법으로 모델을 재사용할 수 있습니다. load_model 로 위 스크린샷처럼 모델을 저장하도록 지정하고, 처음 실행하면 처음부터 loss 로스 1.15 에서 시작. 최종 acc 정확도는 0.906 (90.6%) 90.6% 로 학습된 결과가 mnist_mlp_model.h5 라는 파일로 저장됩니다. 모델 구조 확인하기. 뭐 이건 그냥 참고용으로 보여주기에요. load_model 로 아까 저장했던 mnist_mlp_mod.. [정리] 모두를 위한 딥러닝 10 - 렐루 ReLU & 초기값 정하기 by 김성훈 [정리] 모두를 위한 딥러닝 10 - ReLU & 초기값 정하기 by 김성훈 강의 웹사이트 : http://hunkim.github.io/ml/ Lec = 강의 / Lab = 실습 시그모이드 결과값은 0 이전 1 다음 * 쿠팡 파트너스 활동을 통해 일정액의 수수료를 제공받을 수 있습니다.